Episode 7 – AI Evaluation-Driven Development in the Wild: Road to Anfield
A Study Group Exploring Chip Huyen’s AI Engineering Book

This is the seventh in a series of posts discussing Chip Huyen's AI Engineering book. It tells the fiction story of a junior data scientist at Liverpool FC who uses the book to guide their work leading the team's AI initiatives.
Previous chapter:

In the previous chapter, we put context on how the different evaluation metrics will help to address the usefulness of the LLMs by providing practical implications of each metric. Also, we discussed how AI as a judge can be a good starting place to evaluate our models.

It's 3 pm, the phone rings, and there is chaos everywhere. Slack is getting crazy, everyone wants to review the KPIs Liverpool just lost in the Champions League, and everyone's job is on the line.
Even though Football clubs spend millions of dollars on players, they function like a regular company, with budget limitations. The twist here is that the world gets to see the "failure" and form hard opinions about it in the news and on social media.
Guess this morning's headline!
Liverpool spent millions of dollars on Chatbots only to be eliminated in the round of 16 in the Champions League!
They didn't spend millions on Chatbots, but they did get knocked out in the round of 16 by PSG. Now, the engineering department wants to see the AI work and how it was done.
The product was a chatbot to provide pre-game insights, scouting decisions and live game analysis:

The head of the engineering team is sceptical about the system.
Senior Engineer: How did you check the reliability of this system? The interphase might serve the purpose, but how do you know the quality of the results?
Junior Data scientist: Oh, I took care of that. I checked the system manually by looking at the output.
The lack of a clear, single "correct" answer for many generative tasks, unlike traditional ML metrics (e.g., accuracy, precision, recall), is the most challenging part for transitioning data scientists.
Senior Engineer: Checking manually the response is just the first step. You need to build a robust evaluation system beyond simply checking if the bot provides accurate responses.
Evaluation-driven development, in which there is a clear evaluation criterion before building the application, is key to a successful product. This requires understanding the business context and desired outcomes of the AI application.
Junior Data scientist: Ok, but how do I do it? I mean, since the task is open-ended, I might have problems having a metric in place, like precision or recall, that I cannot implement in the system to track.
Senior Engineer: AI applications are evaluated using four main criteria that differ from traditional ML systems. We have a board meeting, and I will explain these concepts to everyone to align our-self with the system.
Senior Engineer: Good morning, everyone — I want to start this meeting by citing Chip Huyen, who is a reference in the field of AI. This quote summarizes our work ethic in the club.
Before investing time, money, and resources into building an application, it's important to understand how this application will be evaluated. I call this approach evaluation-driven development.
We are building a system to help the team make decisions in three main areas:
Scouting
In-game decision
Tactical decisions
Why does Liverpool fail with all these AI systems that you are referring to?
Senior Engineer: The first thing to understand is that LLMs are not flawless systems; they follow the same operational requirements as any software project. Some portions are different, given the nature of this technology, but the core principles still hold. Our AI systems are evaluated in four main buckets:
Domain-specific: For scouting reports, we evaluate using scouters as subject matter experts to understand their typical workflow and align our application with their judgment.
Generation capabilities: For the in-game decision app, we rely on streaming data coming from the pitch live reports. We applied checkpoints using AI as a judge to evaluate how fluent and coherent a text is.
Factual consistency: It is evaluated either by the given context (Local factual consistency) or by open knowledge (Global consistency). AI as a judge is a series of techniques to evaluate the factual consistency of your outputs.
Factual Consistency: Does the summary contain untruthful or misleading facts that are not supported by the source text?
Source Text: {{Document}}
Summary: {{Summary}}
Does the summary contain factual inconsistency? Answer:
Another form of factual consistency evaluation is by decomposing into individual statements, revising each statement to be self-contained (not using change it for the actual subject), fact-checking each statement, and using AI to determine if the statements are consistent with the search results.
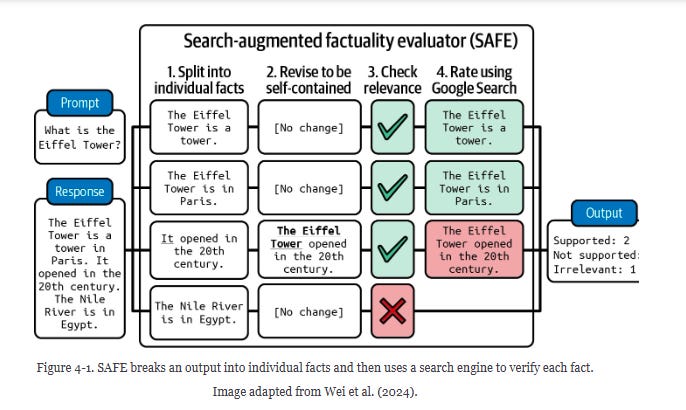
Instruction-following: We need the system to carefully follow the instructions we provided. Tactical decisions are required to be passed as a table following specific points to summarize, such as playing style, tactical defense, tactical attack, and transition points between players.
Roleplaying: It is common to prompt our LLM in a way that assigns roles to our AI, such as "Act as a goalkeeper coach". Evaluating whether our model stays in character is key if we want to make it behave in a certain way.
Cost & Latency: As I mentioned before, football clubs work exactly as any other company; they have a budget and constraints for innovation. We balance quality, latency, and performance. The key is to prioritize the things that matter the most for your company.
Comparison between Gema 3 27B and Gemini 2.5 pro when asked a scouting report about M. Salah. At first glance, both seem good; without systems in place and domain-specific criteria, it is difficult to say which one is better.
Ok, but how does this translate to the team's recent failure?
The key point is that we are building a robust system that considers several dimensions to ensure optimal performance. The idea is to help the team staff make fast and reliable decisions on the spot.
When things go wrong, it is easy to blame AI. It is important to evaluate your application in the context in which you are using it.
Many teams build systems, and when things go wrong, change the model without a clear understanding of what's going on.
The role is not only to make the fancy demo and the shiny stuff, but also to solve business problems and provide an accurate reflection on the existing workflow.
Our goal is to speed up the process, leverage the existing workflow, and improve the business value.
Junior data scientist: The explanation was great! Evaluating an AI system needs a systematic approach to accurately reflect the intentions of our pipeline.
Senior engineer: This is just the starting point. Even though you have an excellent baseline, there is a lot of work to make the AI system reliable and effective. The team is still not happy, many news shows the latest and most impressive models without reflecting the complexity of dedicated use case scenarios.
Junior data scientist: Ok, so should we use the latest model available?
Answering this question will be for the next episode, in which we’ll be learning how to select models and design evaluation pipelines for your AI applications.